
يعني التزييف العميق للفيديو أنه لا يمكنك الوثوق بكل شيء تراه. الآن ، قد يعني التزييف العميق للصوت أنه لم يعد بإمكانك الوثوق بأذنيك. هل كان ذلك حقًا هو إعلان الرئيس الحرب على كندا؟ هل هذا حقًا والدك على الهاتف يسأل عن كلمة مرور بريده الإلكتروني؟
أضف مصدر قلق وجودي آخر إلى قائمة كيف يمكن أن تدمرنا غطرستنا حتمًا. خلال حقبة ريغان ، كانت المخاطر التكنولوجية الحقيقية الوحيدة هي تهديد الحرب النووية والكيميائية والبيولوجية.
في السنوات التالية ، أتيحت لنا الفرصة للاستحواذ على اللزوجة الرمادية لتكنولوجيا النانو والأوبئة العالمية. الآن ، لدينا تقنية التزييف العميق – الأشخاص الذين يفقدون السيطرة على شكلهم أو صوتهم.
ما هو الصوت العميق؟
لقد شاهد معظمنا مقطع فيديو مزيفًا عميقًا ، يتم فيه استخدام خوارزميات التعلم العميق لاستبدال شخص بشبه شخص آخر. الأفضل هو واقعي بشكل مثير للقلق ، والآن حان دور الصوت. التزييف العميق للصوت هو عندما يتم استخدام صوت “مستنسخ” لا يمكن تمييزه عن صوت الشخص الحقيقي لإنتاج صوت اصطناعي.
قال زهيب أحمد ، الرئيس التنفيذي لشركة Resemble AI ، عن تقنية استنساخ الصوت في شركته: “إنه مثل Photoshop للصوت” .
ومع ذلك ، يمكن بسهولة فضح وظائف Photoshop السيئة. قالت شركة أمنية تحدثنا إليها إن الناس عادة ما يخمنون فقط ما إذا كان التزييف العميق للصوت حقيقيًا أو مزيفًا بدقة تصل إلى 57 بالمائة – ليس أفضل من تقليب العملة.
بالإضافة إلى ذلك ، نظرًا لأن العديد من التسجيلات الصوتية عبارة عن مكالمات هاتفية منخفضة الجودة (أو مسجلة في مواقع صاخبة) ، يمكن جعل التزييف العميق للصوت أكثر صعوبة. كلما كانت جودة الصوت أسوأ ، كان من الصعب التقاط تلك الإشارات التي تدل على أن الصوت ليس حقيقيًا.
لكن لماذا يحتاج أي شخص إلى Photoshop للأصوات ، على أي حال؟
الحالة المقنعة للصوت الاصطناعي
هناك بالفعل طلب هائل على الصوت الاصطناعي. وفقًا لأحمد ، “عائد الاستثمار فوري جدًا.”
هذا صحيح بشكل خاص عندما يتعلق الأمر بالألعاب. في الماضي ، كان الكلام هو المكون الوحيد في اللعبة الذي كان من المستحيل إنشاؤه عند الطلب. حتى في العناوين التفاعلية ذات المشاهد بجودة السينما التي يتم تقديمها في الوقت الفعلي ، تكون التفاعلات اللفظية مع الشخصيات التي لا تلعب دائمًا ثابتة بشكل أساسي.
الآن ، على الرغم من ذلك ، استوعبت التكنولوجيا. تتمتع الاستوديوهات بإمكانية استنساخ صوت الممثل واستخدام محركات تحويل النص إلى كلام حتى تتمكن الشخصيات من قول أي شيء في الوقت الفعلي.
هناك أيضًا المزيد من الاستخدامات التقليدية في الإعلان والتقنية ودعم العملاء. هنا ، الصوت الذي يبدو بشريًا حقيقيًا ويستجيب بشكل شخصي وسياقي دون تدخل بشري هو المهم.
شركات استنساخ الصوت متحمسة أيضًا بشأن التطبيقات الطبية. بالطبع ، استبدال الصوت ليس بالأمر الجديد في الطب – اشتهر ستيفن هوكينج باستخدام الصوت الآلي المركب بعد أن فقد صوته في عام 1985. ومع ذلك ، فإن استنساخ الصوت الحديث يعد بشيء أفضل.
في عام 2008 ، أعادت شركة الصوت الاصطناعي CereProc للناقد السينمائي الراحل روجر إيبرت صوته بعد أن أزاله السرطان. نشرت CereProc صفحة ويب تسمح للناس بكتابة الرسائل التي سيتم التحدث بها بعد ذلك بصوت الرئيس السابق جورج بوش.
قال ماثيو آيليت ، كبير المسؤولين العلميين في CereProc: “رأى إيبرت ذلك وفكر ،” حسنًا ، إذا كان بإمكانهم تقليد صوت بوش ، فيجب أن يكونوا قادرين على تقليد صوتي “. ثم طلب إيبرت من الشركة إنشاء صوت بديل ، وهو ما فعلوه من خلال معالجة مكتبة كبيرة من التسجيلات الصوتية.
قال إيليت: “لقد كانت واحدة من المرات الأولى التي قام فيها أي شخص بذلك وكان نجاحًا حقيقيًا”.
في السنوات الأخيرة ، عمل عدد من الشركات (بما في ذلك CereProc) مع جمعية ALS بشأن مراجعة المشروع لتوفير أصوات اصطناعية لأولئك الذين يعانون من مرض التصلب الجانبي الضموري.

كيف يعمل الصوت الاصطناعي
يمر استنساخ الصوت بلحظة في الوقت الحالي ، ويقوم عدد كبير من الشركات بتطوير الأدوات. تشبه AI و Descript تحتوي على عروض توضيحية عبر الإنترنت يمكن لأي شخص تجربتها مجانًا. ما عليك سوى تسجيل العبارات التي تظهر على الشاشة ، وفي غضون دقائق قليلة ، يتم إنشاء نموذج لصوتك.
يمكنك شكر منظمة العفو الدولية – على وجه التحديد ، خوارزميات التعلم العميق – لقدرتها على مطابقة الكلام المسجل بالنص لفهم الصوتيات المكونة لصوتك. ثم يستخدم اللبنات اللغوية الناتجة لتقريب الكلمات التي لم تسمعها تتكلم.
كانت التكنولوجيا الأساسية موجودة منذ فترة ، ولكن كما أشار Aylett ، فإنها تتطلب بعض المساعدة.
قال “تقليد الصوت يشبه إلى حد ما صنع المعجنات”. “كان من الصعب نوعًا ما القيام به وكانت هناك طرق مختلفة لتعديله يدويًا لجعله يعمل.”
احتاج المطورون إلى كميات هائلة من البيانات الصوتية المسجلة للحصول على نتائج مقبولة. ثم ، قبل بضع سنوات ، فتحت البوابات. أثبت البحث في مجال رؤية الكمبيوتر أنه بالغ الأهمية. طور العلماء شبكات الخصومة التوليدية (GANs) ، والتي يمكنها ، لأول مرة ، الاستقراء والتنبؤات بناءً على البيانات الموجودة.
قال Aylett: “بدلاً من رؤية الكمبيوتر لصورة حصان ويقول” هذا حصان “، يمكن أن يجعل نموذجي الآن حصانًا إلى حمار وحشي”. “لذا ، فإن الانفجار في تركيب الكلام الآن بفضل العمل الأكاديمي من رؤية الكمبيوتر.”
كان أحد أكبر الابتكارات في استنساخ الصوت هو التخفيض العام في كمية البيانات الأولية اللازمة لإنشاء صوت. في الماضي ، كانت الأنظمة تحتاج إلى عشرات أو حتى مئات الساعات من الصوت. الآن ، ومع ذلك ، يمكن إنشاء أصوات مختصة من مجرد دقائق من المحتوى.
الخوف الوجودي من عدم الثقة بأي شيء
هذه التكنولوجيا ، إلى جانب الطاقة النووية ، وتكنولوجيا النانو ، والطباعة ثلاثية الأبعاد ، وكريسبر ، مثيرة ومرعبة في نفس الوقت. بعد كل شيء ، كانت هناك بالفعل حالات في الأخبار لخداع الناس من خلال استنساخ الصوت. في عام 2019 ، زعمت شركة في المملكة المتحدة أنها تعرضت للخداع من خلال مكالمة هاتفية صوتية عميقة لتحويل الأموال إلى المجرمين.
لست مضطرًا إلى الذهاب بعيدًا للعثور على مزيفات صوتية مقنعة بشكل مدهش. تعرض قناة Vocal Synthesis على YouTube أشخاصًا مشهورين يقولون أشياء لم يقلوها أبدًا ، مثل قراءة جورج دبليو بوش “In Da Club” بنسبة 50 Cent . إنه على الفور.
في مكان آخر على YouTube ، يمكنك سماع قطيع من الرؤساء السابقين ، بما في ذلك أوباما وكلينتون وريغان ، وهم يغنون موسيقى NWA . تساعد الموسيقى وأصوات الخلفية في إخفاء بعض الأخطاء الروبوتية الواضحة ، ولكن حتى في هذه الحالة غير الكاملة ، فإن الإمكانات واضحة.
لقد جربنا الأدوات الموجودة على Resemble AI و Descript وأنشأنا استنساخًا صوتيًا. يستخدم برنامج Descript محرك استنساخ صوتي كان يسمى في الأصل Lyrebird وكان مثيرًا للإعجاب بشكل خاص. لقد صدمنا الجودة. سماع صوتك يقول أشياء تعرف أنك لم تقلها أبدًا أمر مزعج.
هناك بالتأكيد جودة آلية في الكلام ، ولكن عند الاستماع غير الرسمي ، لن يكون لدى معظم الناس سبب للاعتقاد بأنه كان مزيفًا.
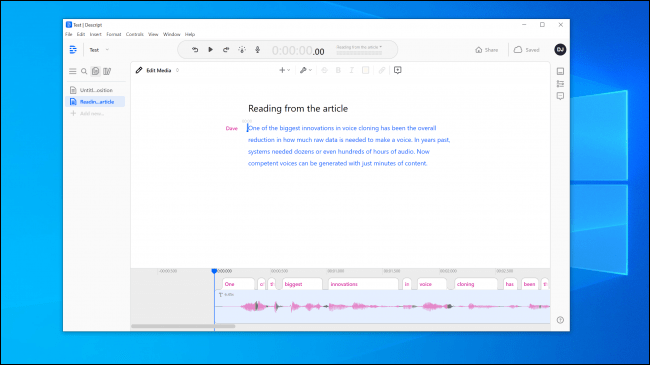
كانت لدينا آمال أكبر في لعبة تشبه الذكاء الاصطناعي. يمنحك الأدوات اللازمة لإنشاء محادثة بأصوات متعددة وتغيير التعبير والعاطفة وسرعة الحوار. ومع ذلك ، لم نعتقد أن النموذج الصوتي يلتقط الصفات الأساسية للصوت الذي استخدمناه. في الواقع ، من غير المرجح أن يخدع أي شخص.
أخبرنا أحد ممثلي الذكاء الاصطناعي المشابه أن “معظم الناس تذهلهم النتائج إذا قاموا بذلك بشكل صحيح.” قمنا ببناء نموذج صوتي مرتين بنتائج مماثلة. لذلك ، من الواضح أنه ليس من السهل دائمًا عمل استنساخ صوت يمكنك استخدامه لسرقة رقمية.
ومع ذلك ، يشعر مؤسس Lyrebird (الذي أصبح الآن جزءًا من Descript) ، Kundan Kumar ، بأننا تجاوزنا بالفعل هذا الحد.
قال كومار: “بالنسبة لنسبة صغيرة من الحالات ، فهي موجودة بالفعل”. “إذا استخدمت الصوت الاصطناعي لتغيير بضع كلمات في خطاب ما ، فهذا أمر جيد بالفعل لدرجة أنك ستواجه صعوبة في معرفة ما الذي تغير.”
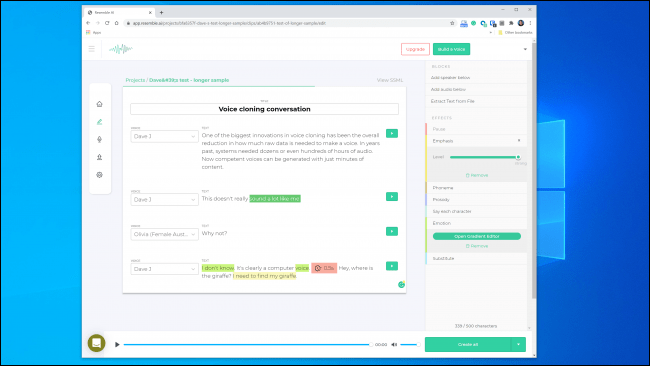
يمكننا أيضًا أن نفترض أن هذه التكنولوجيا ستتحسن بمرور الوقت. ستحتاج الأنظمة إلى صوت أقل لإنشاء نموذج ، وستكون المعالجات الأسرع قادرة على بناء النموذج في الوقت الفعلي. سوف يتعلم الذكاء الاصطناعي الأكثر ذكاءً كيفية إضافة إيقاع أكثر إقناعًا شبيهًا بالإنسان والتركيز على الكلام دون أن يكون لديك مثال للعمل منه.
مما يعني أننا قد نقترب أكثر من التوافر الواسع النطاق لاستنساخ الصوت بسهولة.
أخلاقيات صندوق باندورا
يبدو أن معظم الشركات العاملة في هذا المجال مستعدة للتعامل مع التكنولوجيا بطريقة آمنة ومسؤولة. يشبه الذكاء الاصطناعي ، على سبيل المثال ، قسم “الأخلاقيات” بالكامل على موقعه على الويب ، والمقتطفات التالية مشجعة:
“نحن نعمل مع الشركات من خلال عملية صارمة للتأكد من أن الصوت الذي تستنسخه قابل للاستخدام من قبلهم وأن لديهم الموافقات المناسبة مع الممثلين الصوتيين.”
وبالمثل ، قال كومار إن Lyrebird كانت قلقة بشأن سوء الاستخدام منذ البداية. لهذا السبب الآن ، كجزء من Descript ، يسمح للأشخاص فقط باستنساخ أصواتهم. في الواقع ، يتطلب كل من Resemble و Descript أن يسجل الأشخاص عيناتهم مباشرة لمنع استنساخ الصوت غير الحسّي.
من المشجع أن اللاعبين التجاريين الرئيسيين قد فرضوا بعض الإرشادات الأخلاقية. ومع ذلك ، من المهم أن تتذكر أن هذه الشركات ليست حراسًا لهذه التكنولوجيا. هناك عدد من الأدوات مفتوحة المصدر موجودة بالفعل في البرية ، والتي لا توجد قواعد لها. وفقًا لهنري أجدر ، رئيس استخبارات التهديدات في Deeptrace ، لا تحتاج أيضًا إلى معرفة تشفير متقدمة لإساءة استخدامها.
قال أجدر: “لقد تحقق الكثير من التقدم في الفضاء من خلال العمل التعاوني في أماكن مثل GitHub ، باستخدام تطبيقات مفتوحة المصدر للأوراق الأكاديمية المنشورة سابقًا”. “يمكن استخدامه من قبل أي شخص لديه إتقان متوسط في الترميز.”
لقد شاهد محترفو الأمن كل هذا من قبل
حاول المجرمون سرقة الأموال عبر الهاتف قبل وقت طويل من إمكانية استنساخ الصوت ، وكان خبراء الأمن دائمًا على أهبة الاستعداد لاكتشافها ومنعها. تحاول شركة الأمان Pindrop إيقاف الاحتيال المصرفي عن طريق التحقق مما إذا كان المتصل هو من يدعي أنه من الصوت. في عام 2019 وحده ، ادعى Pindrop أنه قام بتحليل 1.2 مليار تفاعل صوتي ومنع حوالي 470 مليون دولار من محاولات الاحتيال.
قبل استنساخ الصوت ، جرب المحتالون عددًا من الأساليب الأخرى. أبسطها كان مجرد الاتصال من مكان آخر بمعلومات شخصية عن العلامة.
قال الرئيس التنفيذي لشركة Pindrop ، Vijay Balasubramaniyan: “يتيح لنا توقيعنا الصوتي تحديد أن المكالمة تأتي بالفعل من هاتف Skype في نيجيريا بسبب خصائص الصوت”. “بعد ذلك ، يمكننا مقارنة ذلك بمعرفة أن العميل يستخدم هاتف AT&T في أتلانتا.”
كما جعل بعض المجرمين وظائفهم من استخدام أصوات الخلفية للتخلص من مندوبي البنوك.
قال بالاسوبرامانيان: “هناك محتال نطلق عليه تشيكن مان كان دائمًا لديه ديوك في الخلفية”. “وهناك سيدة واحدة استخدمت طفلًا يبكي في الخلفية لإقناع وكلاء مركز الاتصال بشكل أساسي ،” مرحبًا ، أنا أمر بوقت عصيب “للحصول على التعاطف.”
ثم هناك المجرمين الذكور الذين يلاحقون الحسابات المصرفية للنساء.
أوضح بالاسوبرامانيان: “إنهم يستخدمون التكنولوجيا لزيادة وتيرة أصواتهم ، ليبدو أكثر أنوثة”. يمكن أن تكون هذه ناجحة ، ولكن “في بعض الأحيان ، يفسد البرنامج ويظهرون مثل ألفين والسناجب.”
بالطبع ، يعد استنساخ الصوت مجرد أحدث تطور في هذه الحرب المتصاعدة باستمرار. لقد ضبطت شركات الأمن بالفعل محتالين يستخدمون الصوت الاصطناعي في هجوم واحد على الأقل من عمليات الصيد بالرمح.
قال بالاسوبرامانيان: “مع الهدف الصحيح ، يمكن أن تكون المدفوعات ضخمة”. “لذلك ، من المنطقي تخصيص الوقت لإنشاء صوت مركب للفرد المناسب.”
هل يمكن لأي شخص أن يعرف ما إذا كان الصوت مزيفًا؟

عندما يتعلق الأمر بمعرفة ما إذا كان الصوت مزيفًا ، فهناك أخبار جيدة وأخرى سيئة. السيئ هو أن استنساخ الصوت يتحسن كل يوم. أصبحت أنظمة التعلم العميق أكثر ذكاءً وتنتج أصواتًا أكثر واقعية تتطلب صوتًا أقل لإنشاءها.
كما يمكنك أن تقول من مقطع الفيديو هذا للرئيس أوباما وهو يطلب من MC Ren اتخاذ الموقف ، فقد وصلنا بالفعل إلى النقطة التي يمكن أن يبدو فيها النموذج الصوتي عالي الدقة والمصمم بعناية مقنعًا جدًا للأذن البشرية.
كلما زاد طول مقطع الصوت ، زادت احتمالية ملاحظتك لوجود شيء خاطئ. مع ذلك ، بالنسبة إلى المقاطع القصيرة ، قد لا تلاحظ أنها اصطناعية – خاصة إذا لم يكن لديك سبب للتشكيك في شرعيتها.
كلما كانت جودة الصوت أكثر وضوحًا ، كان من الأسهل ملاحظة علامات التزييف العميق للصوت. إذا كان شخص ما يتحدث مباشرة إلى ميكروفون بجودة الاستوديو ، فستتمكن من الاستماع عن كثب. لكن تسجيل مكالمة هاتفية رديئة الجودة أو محادثة يتم التقاطها على جهاز محمول باليد في مرآب سيارات صاخب سيكون من الصعب تقييمه.
الخبر السار هو أنه حتى لو واجه البشر مشكلة في الفصل بين الحقيقي والمزيف ، فإن أجهزة الكمبيوتر لا تملك نفس القيود. لحسن الحظ ، أدوات التحقق الصوتي موجودة بالفعل. لدى Pindrop نظام يضع أنظمة التعلم العميق في مواجهة بعضها البعض. يستخدم كلاهما لاكتشاف ما إذا كانت العينة الصوتية هي الشخص المفترض أن تكون. ومع ذلك ، فإنه يفحص أيضًا ما إذا كان بإمكان الإنسان إصدار جميع الأصوات في العينة.
اعتمادًا على جودة الصوت ، تحتوي كل ثانية من الكلام على ما بين 8000 إلى 50000 عينة بيانات يمكن تحليلها.
أوضح بالاسوبرامانيان أن “الأشياء التي نبحث عنها عادةً هي قيود على الكلام بسبب التطور البشري”.
على سبيل المثال ، صوتان صوتيان لهما أدنى فصل ممكن عن بعضهما البعض. هذا لأنه ليس من الممكن جسديًا قولها بشكل أسرع نظرًا للسرعة التي يمكن بها لعضلات الفم والحبال الصوتية إعادة تكوين نفسها.
قال بالاسوبرامانيان: “عندما ننظر إلى الصوت المركب ، فإننا نرى أحيانًا أشياء ونقول ،” لم يكن من الممكن أبدًا إنشاء هذا بواسطة إنسان لأن الشخص الوحيد الذي يمكن أن ينتج هذا يحتاج إلى رقبة طولها سبعة أقدام. ”
هناك أيضًا فئة من الأصوات تسمى “الاحتكاكات”. تتشكل عندما يمر الهواء عبر انقباض ضيق في حلقك عندما تنطق أحرف مثل f و s و v و z. يصعب على أنظمة التعلم العميق إتقان الاحتكاكات لأن البرنامج يواجه صعوبة في تمييزها عن الضوضاء.
لذلك ، على الأقل في الوقت الحالي ، يتعثر برنامج استنساخ الصوت من حقيقة أن البشر عبارة عن أكياس من اللحم تتدفق الهواء عبر ثقوب في أجسادهم للتحدث.
قال بالاسوبرامانيان: “ما زلت أمزح أن التزييف العميق مزيف للغاية”. وأوضح أنه من الصعب جدًا على الخوارزميات تمييز نهايات الكلمات عن ضوضاء الخلفية في التسجيل. ينتج عن هذا العديد من النماذج الصوتية ذات الكلام الذي يتخلف أكثر مما يفعل البشر.
قال بالاسوبرامانيان: “عندما ترى الخوارزمية أن هذا يحدث كثيرًا ، من الناحية الإحصائية ، تصبح أكثر ثقة في أن الصوت تم إنشاؤه بدلاً من الصوت البشري”.
يتعامل برنامج Resemble AI أيضًا مع مشكلة الكشف بشكل مباشر مع Resemblyzer ، وهي أداة تعلم عميق مفتوحة المصدر متاحة على GitHub . يمكنه اكتشاف الأصوات المزيفة وإجراء التحقق من السماعة.
يتطلب اليقظة
من الصعب دائمًا تخمين ما قد يحمله المستقبل ، ولكن من شبه المؤكد أن هذه التكنولوجيا ستتحسن فقط. أيضًا ، يمكن أن يكون أي شخص ضحية – ليس فقط الأفراد البارزين ، مثل المسؤولين المنتخبين أو المديرين التنفيذيين للمصارف.
وتوقع بالاسوبرامانيان “أعتقد أننا على شفا أول اختراق صوتي حيث تُسرق أصوات الناس”.
في الوقت الحالي ، على الرغم من ذلك ، فإن مخاطر العالم الحقيقي من التزييف العميق للصوت منخفضة. هناك بالفعل أدوات يبدو أنها تقوم بعمل جيد جدًا في اكتشاف الفيديو التركيبي.
بالإضافة إلى ذلك ، لا يتعرض معظم الأشخاص لخطر التعرض لهجوم. وفقًا لـ Ajder ، فإن اللاعبين التجاريين الرئيسيين “يعملون على حلول مخصصة لعملاء محددين ، ومعظمهم لديهم إرشادات أخلاقية جيدة إلى حد ما فيما يتعلق بمن سيعملون وما لن يعملوا معه.”
ومع ذلك ، فإن التهديد الحقيقي ينتظرنا ، كما أوضح أجدر:
“سيكون Pandora’s Box أشخاصًا يجمعون تطبيقات مفتوحة المصدر للتكنولوجيا في تطبيقات أو خدمات سهلة الاستخدام بشكل متزايد ، أو خدمات لا تحتوي على هذا النوع من التدقيق الأخلاقي الذي تقوم به الحلول التجارية في الوقت الحالي.”
ربما يكون هذا أمرًا لا مفر منه ، لكن شركات الأمن تقوم بالفعل بنشر الكشف الصوتي المزيف في مجموعات أدواتها. ومع ذلك ، فإن البقاء بأمان يتطلب اليقظة.
قال أجدر: “لقد فعلنا ذلك في مناطق أمنية أخرى”. “تقضي الكثير من المؤسسات الكثير من الوقت في محاولة فهم ما هي ثغرة يوم الصفر التالية ، على سبيل المثال. الصوت الاصطناعي هو ببساطة الحد التالي “.

